 defer 链如何被遍历执行
defer 链如何被遍历执行
为了在退出函数前执行一些资源清理的操作,例如关闭文件、释放连接、释放锁资源等,会在 函数里写上多个 defer 语句,被 defered 的函数,以 “先进后出” 的顺序,在 RET 指令前得以执行。
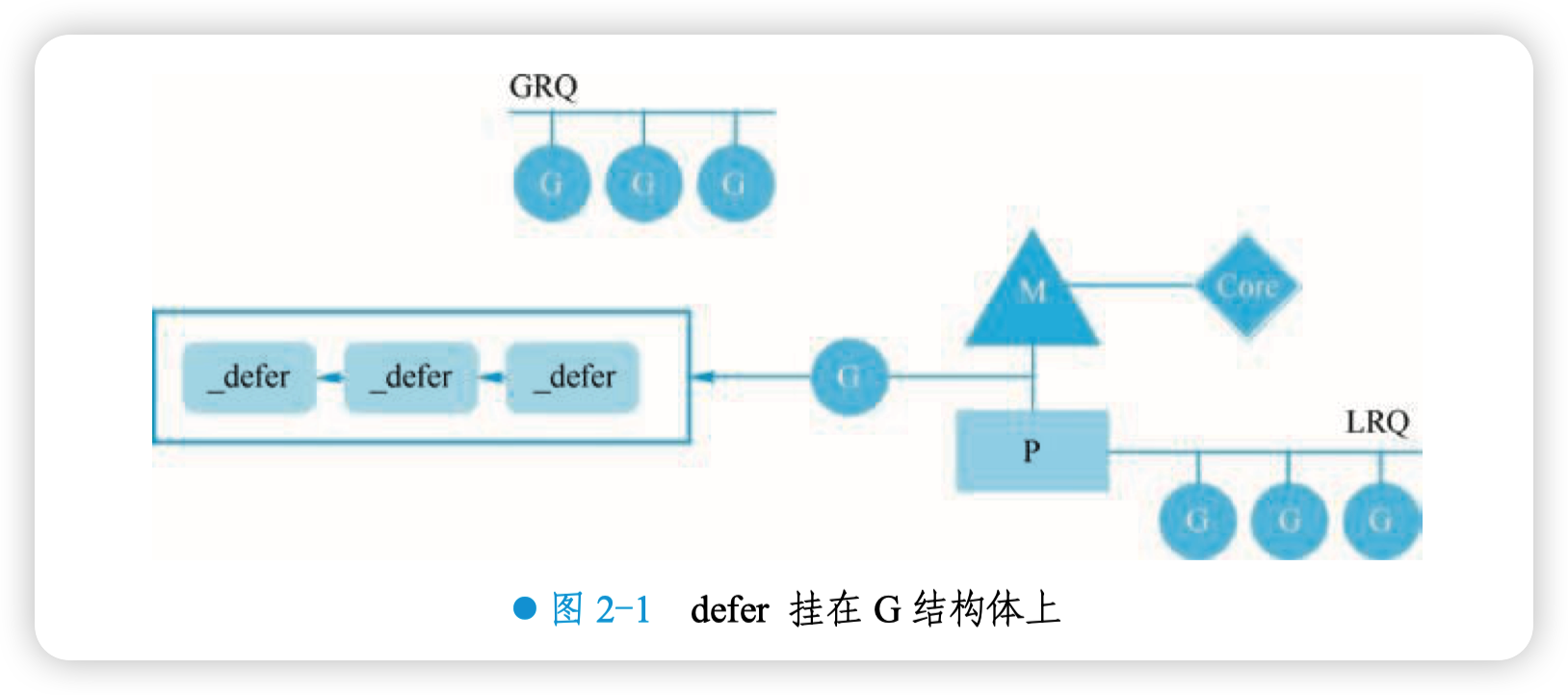
在一条函数调用链中,多个函数中会出现多个 defer 语句。例如:a ()→b ()→c () 中,每个函数 里都有 defer 语句,而这些 defer 语句会创建对应个数的 _defer 结构体,这些结构体以链表的形 式 “挂” 在 G 结构体下。看起来像这样,如图 2-1 所示。
多个 _defer 结构体形成一个链表,G 结构体中某个字段指向此链表。
在编译器的 “加持下”,defer 语句会先调用 deferporc 函数,new 一个_defer 结构体,挂到 G 上。当然,调用 new 之前会优先从当前 G 所绑定的 P 的 defer pool 里取,没取到则会去全局的 defer pool 里取,实在没有的话才新建一个。这是 Go runtime 里非常常见的操作,即设置多级缓存, 提升运行效率。
在执行 RET 指令之前(注意不是 return 之前),调用 deferreturn 函数完成 _defer 链表的遍 历, 执行完这条链上所有被 defered 的函数(如关闭文件、释放连接、释放锁资源等)。 在 deferreturn 函数的最后,会使用 jmpdefer 跳转到之前被 defered 的函数,这时控制权从 runtime 转 移到了用户自定义的函数。这只是执行了一个被 defered 的函数,那这条链上其他的被 defered 的 函数,该如何得到执行?
答案就是控制权会再次交给 runtime,并再次执行 deferreturn 函数,完成 defer 链表的遍历。 那这一切是如何完成的?
这就要从 Go 汇编的栈帧说起了。先看一个汇编函数的声明:
TEXT runtime·gogo(SB), NOSPLIT, $16-8
最后两个数字分别表示:①gogo 函数的栈帧大小为 16B,即函数的局部变量和为调用子函数 准备的参数、返回值共需要 16B 的栈空间;②参数和返回值的大小加起来是 8B。
实际上,gogo 函数的声明是这样的:
// func gogo(buf *gobuf)
参数及返回值的大小是给调用者 “看” 的,调用者根据这个数字可以构造栈:准备好被调函数需要的参数及返回值。
典型的函数调用场景下参数布局图如图 2-2 所示:
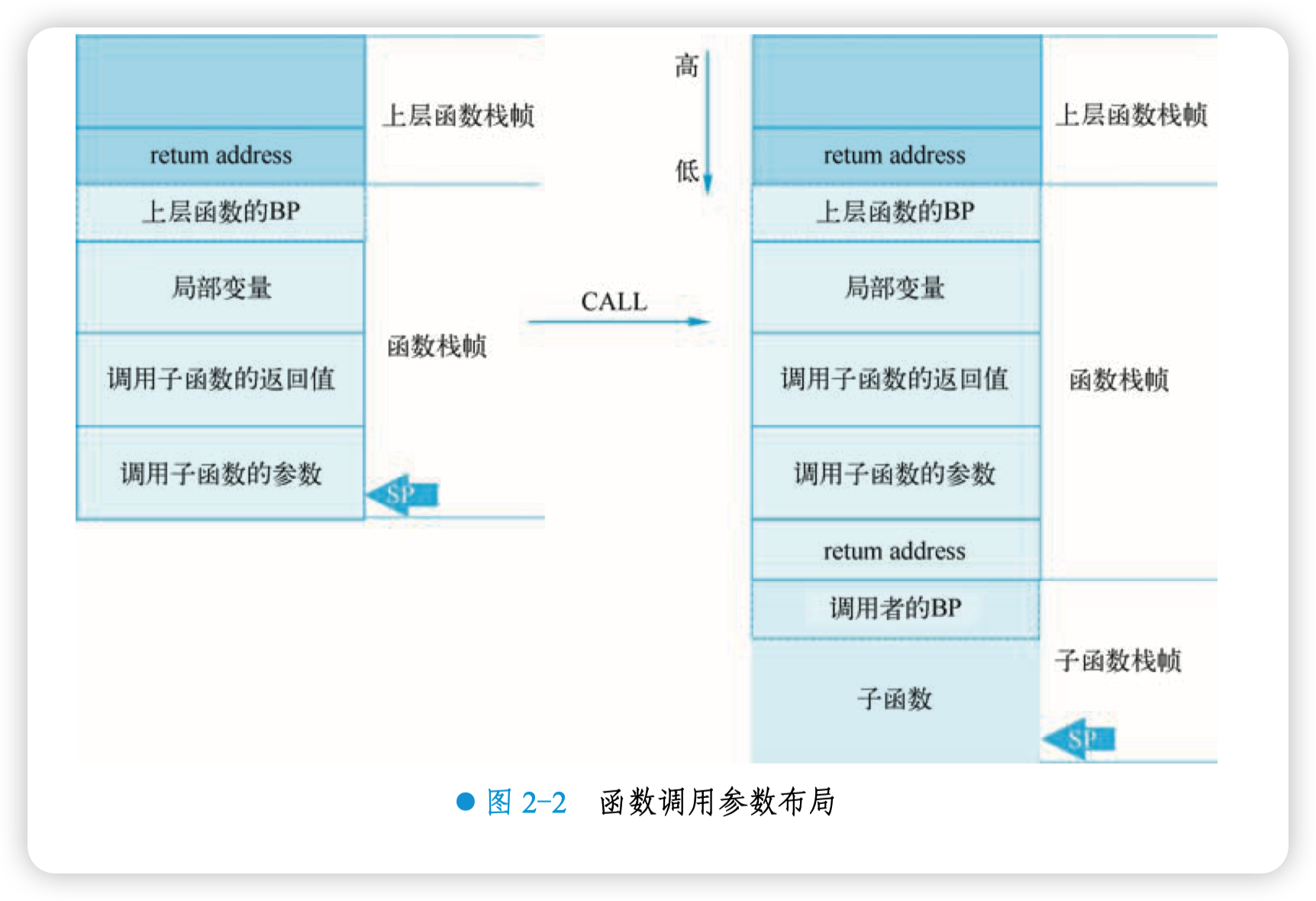
图 2-2 中左半部分,主调函数准备好调用子函数的参数及返回值,执行 CALL 指令,将返回 地址 return address 压入栈顶,相当于执行了 PUSH IP。之后,将 BP 寄存器的值入栈,相当于执 行了 PUSH BP,再 JMP 到被调函数。BP 指的是栈基址指针,SP 是指栈顶指针。
图中 return address 表示子函数执行完毕后,返回到上层函数中调用子函数语句的下一条要执 行的指令,它属于 caller 的栈帧;而调用者的 BP 则属于被调函数的栈帧。
子函数执行完毕后,执行 RET 指令:首先将子函数栈底部的值(图 2-2 中的调用者的 BP) 赋到 CPU 的 BP 寄存器中,于是 BP 指向上层函数的 BP;再将 return address 赋到 IP 寄存器 中,这时 SP 回到左图所示的位置。相当于还原了整个调用子函数的现场,好像一切都没发生过, 而实际上 “调用子函数的返回值” 已经被填充上了正确的值,例如两个数相加的结果;接着,CPU 继续执行 IP 寄存器里的下一条指令。
再回到 defer 上来,其实在构造 _defer 结构体的时候,需要将当前函数的 SP、被 defered 的 函数指针保存到 _defer 结构体中。并且会将被 defered 的函数所需要的参数复制到和 _defer 结构 体相邻的位置。最终在调用被 defered 的函数的时候,用的就是这时被复制的值,相当于使用了它 的一个 “快照”,如果此参数不是指针或引用类型的话,会产生一些意料之外的 bug。
最后,在 deferreturn 函数里,遍历 _defer 链表,这些被 defered 的函数得以执行,_defer 链 表也会被逐渐 “消耗” 完。
来看一个例子:
package main
import "fmt"
func sum(a, b int) {
c := a + b
fmt.Println("sum:" , c)
}
func f(a, b int) {
defer sum(a, b)
fmt.Printf("a: %d, b: %d\n", a, b)
}
func main() {
a, b := 1, 2
f(a, b)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
执行完 f 函数时,最终会进入 deferreturn 函数:
// src/runtime/panic.go
func deferreturn(arg0 uintptr) {
gp := getg()
d := gp._defer
if d == nil {
return
}
......
switch d.siz {
case 0:
// Do nothing.
case sys.PtrSize:
*(*uintptr)(unsafe.Pointer(&arg0)) = *(*uintptr)(deferArgs(d))
default:
memmove(unsafe.Pointer(&arg0), deferArgs(d), uintptr(d.siz)) // 移动参数
}
fn := d.fn
d.fn = nil
gp._defer = d.link
freedefer(d)
_ = fn.fn
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0)))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
因为是在遍历 _defer 链表,所以得加入一个终止的条件:
d := gp._defer
if d == nil {
return
}
2
3
4
当 _defer 链表为空的时候,终止遍历。在后面的代码里会看到,每执行完一个被 defered 的 函数后,都会将 _defer 结构体从链表中删除并回收,所以 _defer 链表会越来越短,直至为空。
函数中 switch 语句里要做的就是准备好被 defered 的函数(例子中就是 sum 函数)所需要的 a、b 两个 int 型参数。参数从哪来?从 _defer 结构体相邻的位置,还记得吗,这是在 deferproc 函数里复制过去的。deferArgs (d) 返回的就是当时复制的目的地址。 那要复制到哪去?答案是: unsafe.Pointer (&arg0)。因为,arg0 是 deferreturn 函数的参数,而在 Go 汇编中,一个函数的参数 是由它的主调函数准备的。因此 arg0 的地址实际上就是它的上层函数(在这里就是 f 函数)的栈 上放调用子函数参数的位置,回忆一下前面讲函数栈帧的图。
函数的最后,通过 jmpdefer 跳转到被 defered 的 sum 函数:
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0)))
这里 fn 就是 sum 函数。核心在于 jmpdefer 所做的事:
// src/runtime/asm_amd64.s
TEXT runtime·jmpdefer(SB), NOSPLIT, $0-16
MOVQ fv+0(FP), DX // fn,defer 的函数的地址
MOVQ argp+8(FP), BX
LEAQ -8(BX), SP // caller sp after CALL
MOVQ -8(SP), BP// restore BP as if deferreturn returned (harmless if framepointers not in use)
SUBQ $5, (SP)// return to CALL again
MOVQ 0(DX), BX
JMP BX // but first run the deferred function
2
3
4
5
6
7
8
9
10
首先将 sum 函数的地址放到 DX 寄存器中,最后通过 JMP 指令去执行。
MOVQ argp+8(FP), BX
LEAQ -8(BX), SP // 执行 CALL 指令后 f 函数的栈顶
2
这两行实际上是调整了下当前 SP 寄存器的值,因为 argp+8 (FP) 实际上是 jmpdefer 的第二个 参数(它在 deferreturn 函数中),它指向 f 函数栈帧中的刚被复制过来的 sum 函数的参数。而 8 (BX) 就代表了 f 函数调用 deferreturn 的返回地址,实际上就是 f 调用 deferreturn 函数的下一 条指令地址。
接着,MOVQ -8 (SP), BP 这条指令重置了 BP 寄存器,使它指向了 f 栈帧 的 BP。这样, SP、BP 寄存器回到了 f 函数调用 deferreturn 之前的状态:f 刚准备好调用 deferreturn 的参数, 并且把返回值压栈了。也就相当于抛弃了 deferreturn 函数的栈帧。
接着 SUBQ $5, (SP) 把返回地址减少了 5B,刚好是一个 CALL 指令的长度。什么意思? 当执行完 deferreturn 函数之后,执行流程会返回到 CALL deferreturn 的下一条指令,将这个值减 少 5B,也就又回到了 CALL deferreturn 指令,从而实现了 “递归地” 调用 deferreturn 函数的效 果。当然,栈却不会再增长。
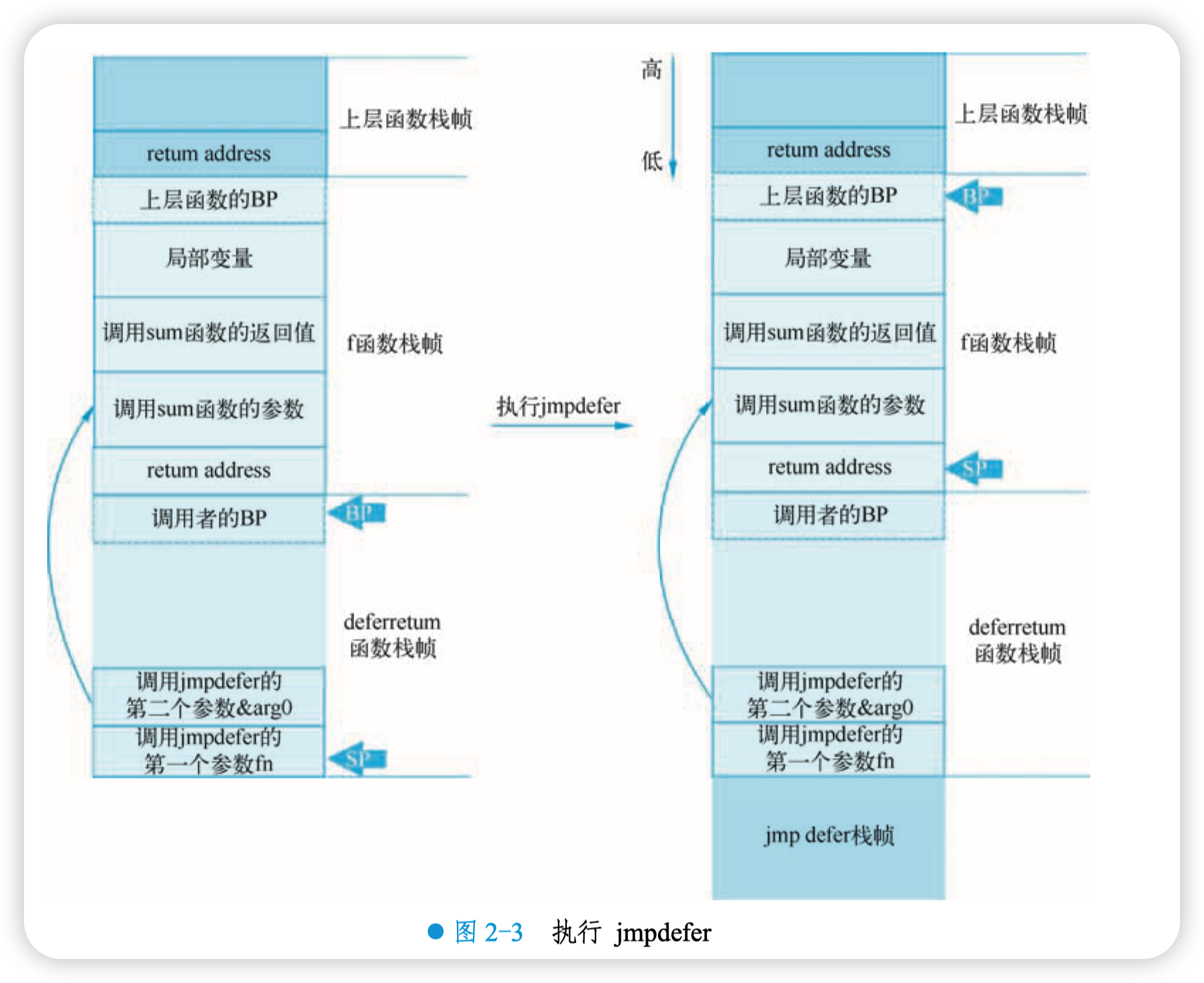
上面所描述的整个过程,结合图 2-3 会更容易理解:
jmpdefer 函数的最后会执行 sum 函数,看起来就像是 f 函数直接调用 sum 函数一样,参 数、返回值都是就绪的。
等到 sum 函数执行完,执行流程就会跳转到 call deferreturn 指令处重新进入 deferreturn 函 数,遍历完所有的_defer 结构体,执行完所有的被 defered 的函数,才真正执行完 deferretrun 函 数,如图 2-4 所示。
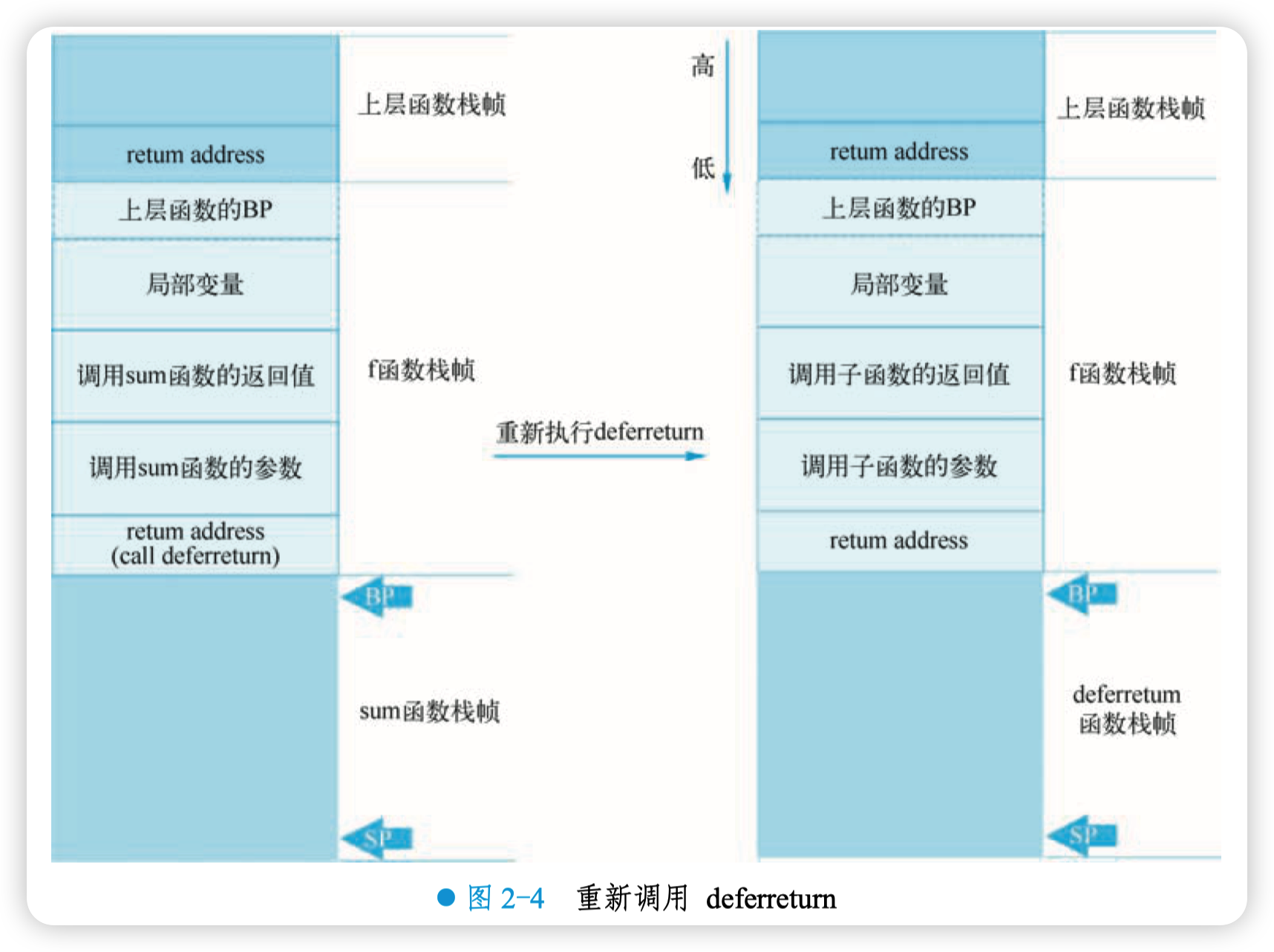
综上所述,实现遍历 defer 链表的关键就是 jmpdefer 函数所做的一些 “见不得人” 的工作, 将调用 deferreturn 函数的返回地址减少了 5 个字节,使得被 defered 的函数执行完后,又回到 CALL deferreturn 指令处,从而实现 “递归地” 调用 deferreturn 函数,完成 _defer 链表的遍历。