 通道的底结构
通道的底结构
# 数据结构
底层数据结构直接看源码:
// src/runtime/chan.go
type hchan struct {
qcount uint // chan 里元素数量
dataqsiz uint // chan 底层循环数组的长度
buf unsafe.Pointer // 指向底层循环数组的指针,只针对有缓冲的 channel
elemsize uint16 // chan 中元素大小
closed uint32 // chan 是否被关闭的标志
elemtype *_type // chan 中元素类型
sendx uint // 已发送元素在循环数组中的索引
recvx uint // 已接收元素在循环数组中的索引
recvq waitq // 等待接收的 goroutine 队列
sendq waitq // 等待发送的 goroutine 队列
lock mutex // 保护 hchan 中所有字段以及 sudog 上一些字段
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
关于字段的含义都写在注释里了,来重点看几个字段:
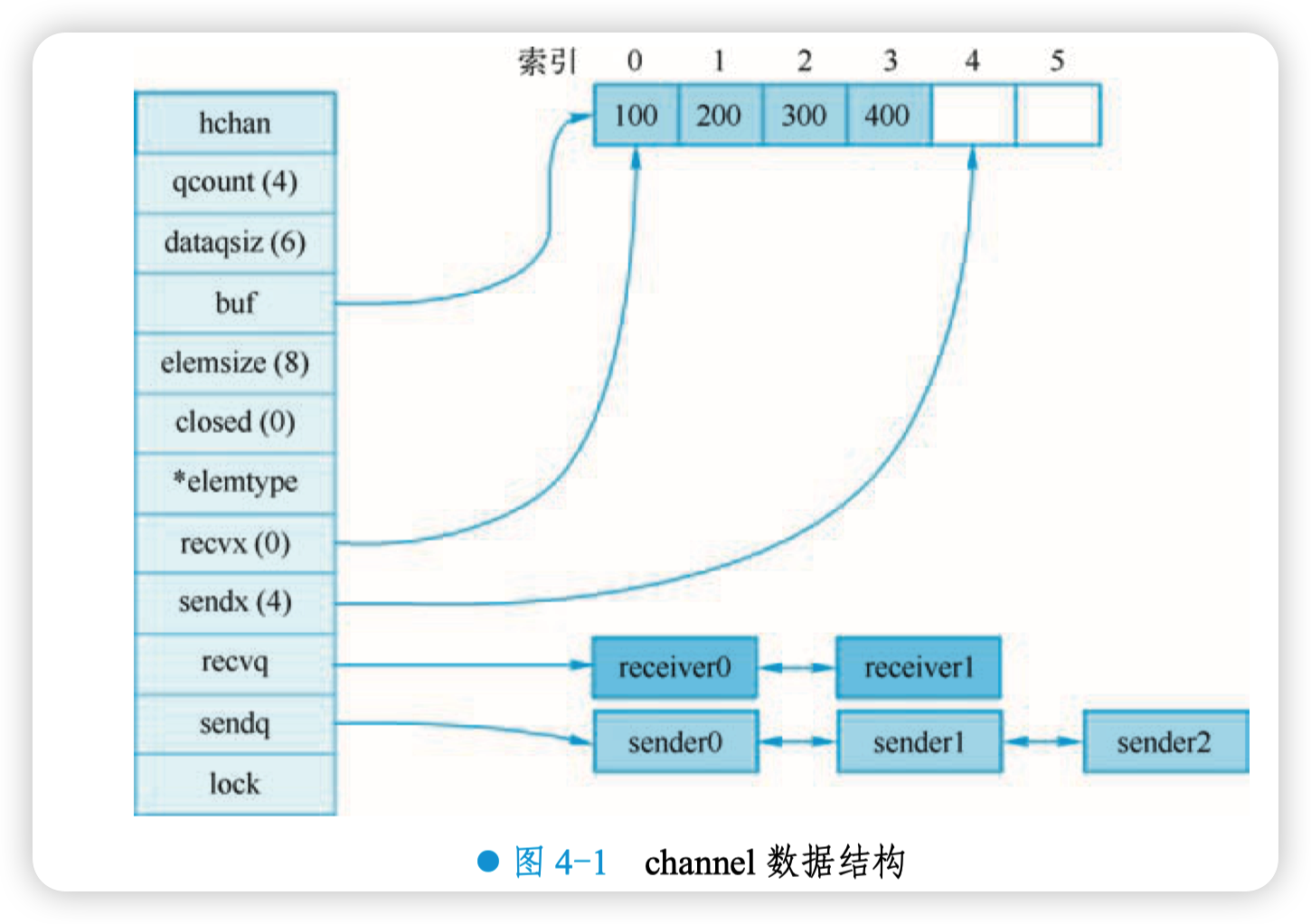
字段 buf 指向底层循环数组,只有缓冲型的 channel 才有效。
字段 sendx,recvx 均指向底层循环数组,表示当前可以发送和接收的元素位置索引值(相对 于底层数组)。
字段 sendq,recvq 分别表示被阻塞的 goroutine,这些 goroutine 由于尝试读取 channel 或向 channel 发送数据而被阻塞。阻塞的原因是 channel 为空,没有元素可被读取或者 channel 已满, 无法向其发送更多的元素。
字段 waitq 是 sudog 的一个双向链表,而 sudog 实际上是对 goroutine 的一个封装:
// src/runtime/chan.go
type waitq struct {
first *sudog
last *sudog
}
2
3
4
5
6
字段 lock 用来保证每个读 channel 或写 channel 的操作都是原子的操作。
例如,创建一个容量为 6 的,元素为 int 型的 channel 数据结构如图 4-1 所示。
# 创建过程
channel 有两个方向:发送和接收。理论上来说,可以创建一个只发送或只接收的通道,但是这种通道创建出来后,怎么使用呢?一个只能发的通道,怎么接收呢?同样,一个只能收的通道, 如何向其发送数据呢?答案是作为函数参数,只发送或只接收可以保证函数内部对 channel 的操作是 “安全” 的。
使用 make 创建一个能收能发的通道:
// 无缓冲通道
ch1 := make(chan int)
// 有缓冲通道
ch2 := make(chan int, 10)
2
3
4
通过对汇编分析,可以得到最终创建 chan 的函数是 makechan:
func makechan(t *chantype, size int64) *hchan
从函数原型来看,创建的 chan 是一个指针。所以能在函数间直接传递 channel 本身,而不用 传递 channel 的指针。
具体来看下代码:
// src/runtime/chan.go
// hchanSize 的大小
const hchanSize = unsafe.Sizeof(hchan{}) + uintptr(-int(unsafe.Sizeof(hchan{}))&(maxAlign-1))
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// 省略了检查 channel size,align 的代码
// ……
// 计算 chan 需要的内存大小,以及计算是否超出最大值而溢出
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
var c *hchan
switch {
case mem == 0:
// channel 容量或元素大小为零
// 1. 非缓冲型的,buf 没用,直接指向 chan 起始地址处
// 2. 缓冲型的,能进入到这里,说明元素无指针且元素类型为 struct{},也无影响
// 因为只会用到接收和发送游标,不会真正复制东西到 c.buf 处(这会覆盖 chan 的内容)
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr() // 实际上 c.buf = unsafe.Pointer(&c.buf)
case elem.ptrdata == 0:
// 如果 hchan 结构体中不含指针,GC 就不会扫描 chan 中的元素
// 只分配 "hchan 结构体大小 + 元素大小*个数" 的内存
// 只进行一次内存分配操作
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// 进行两次内存分配操作
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size) // 循环数组长度
lockInit(&c.lock, lockRankHchan)
// ……
return c // 返回 hchan 指针
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
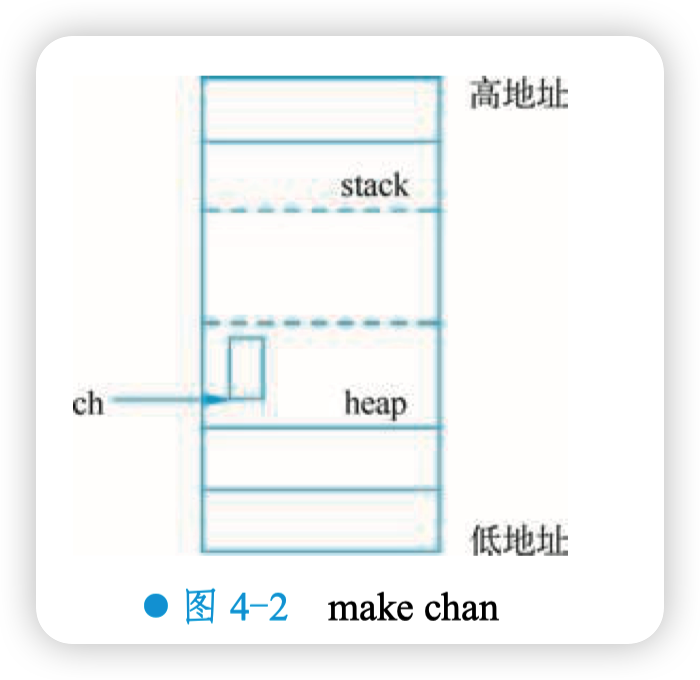
主要是分配内存,初始化相关的字段,新建一个 chan 后,在堆上分配分存,如图 4-2 所示。
# 接收过程
# 1. 源码分析
先来看接收相关的源码,在理解了接收的具体过程之后,再根据一个实际的例子来具体研究。
接收操作有两种写法,一种带 “ok”,反应 channel 是否关闭;一种不带 “ok”,当接收到相应类型的零值时无法知道是真实的发送者发送过来的值,还是 channel 被关闭后,channel 返回给接收者的默认类型的零值。两种写法,都有各自的应用场景。
经过编译器的处理后,这两种写法最后对应源码里如下两个函数:
// src/runtime/chan.go
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
2
3
4
5
6
7
8
9
10
函数 chanrecv1 处理不带 “ok” 情形, chanrecv2 则通过返回 “received” 这个字段来得知 channel 是否被关闭。接收值则比较特殊,会被 “放到” 参数 elem 所指向的地址,这很像 C/C++ 里的写法:通过指针 “携带” 返回值。如果代码里忽略了接收值,这里的 elem 传的实参为 nil。
两者最终都会调用 chanrecv 函数:
// src/runtime/chan.go
// chanrecv 函数接收 channel c 的元素并将其写入 ep 所指向的内存地址
// 如果 ep 是 nil,说明调用者忽略了接收值
// 如果 block == false,即非阻塞型接收,在没有数据可接收的情况下,返回 (false, false)
// 否则,如果 c 处于关闭状态,将 ep 指向的地址清零,返回 (true, false)
// 否则,用返回值填充 ep 指向的内存地址。返回 (true, true)
// 如果 ep 非空,则应该指向堆或者函数调用者的栈
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// ...
// 如果是一个 nil 的 channel
if c == nil {
if !block { // 如果是非阻塞调用,直接返回 (false, false)
return
}
// 否则,从一个 nil 的 channel 接收,对应的 goroutine 被挂起,永远不会被唤醒
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// 快速通道:对于非阻塞调用,不用获取锁,快速检测失败
if !block && empty(c) { // 对于非阻塞型调用,且 channel 是空的
// 当观测到 channel 是空的时候,再来观察 channel 是否是 closed
if atomic.Load(&c.closed) == 0 {
// 因为 channel 不可能被重复打开,所以前一个观测的时候 channel 也是未关闭的
// 因此在这种情况下可以直接宣布接收失败,返回 (false, false)
return
}
// channel 已经被关闭,并且不会再打开。再检查一下 channel 是否还有数据
if empty(c) {
// ……
// 如果要接收数据,那返回零值
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false // 被选中,但没收到数据
}
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
lock(&c.lock)
// channel 已关闭,并且循环数组 buf 里没有元素
// 这里可以处理非缓冲型关闭 和 缓冲型关闭但 buf 无元素的情况
// 相对的情况是,即使是关闭状态,但在缓冲型的 channel,buf 里有元素的情况下还能接收到元素
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
// 从一个已关闭的 channel 执行接收操作,且未忽略返回值
// 那么接收的值将是一个该类型的零值
// typedmemclr 根据类型清理相应地址的内存
typedmemclr(c.elemtype, ep)
}
return true, false // 从一个已关闭的 channel 接收,selected 会返回 true
}
// 等待发送队列里有 goroutine 存在,说明 buf 是满的
// 这有可能是:
// 1. 非缓冲型的 channel
// 2. 缓冲型的 channel,但 buf 满了
// 针对 1,直接进行内存复制(从 sender goroutine -> receiver goroutine)
// 针对 2,接收到循环数组头部的元素,并将发送者的元素放到循环数组尾部
if sg := c.sendq.dequeue(); sg != nil {
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
// 缓冲型,buf 里有元素,可以正常接收
if c.qcount > 0 {
qp := chanbuf(c, c.recvx) // 直接从循环数组里找到要接收的元素
// ……
// 代码里,没有忽略要接收的值,不是 "<- ch",而是 "val <- ch",ep 指向 val
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp) // 清理掉循环数组里相应位置的值
c.recvx++ // 接收游标向前移动
if c.recvx == c.dataqsiz {
c.recvx = 0 // 接收游标归零
}
c.qcount-- // buf 数组里的元素个数减 1
unlock(&c.lock) // 解锁
return true, true
}
if !block { // 非阻塞接收,解锁。selected 返回 false,因为没有接收到值
unlock(&c.lock)
return false, false
}
// 接下来就是处理被阻塞的情况了
// 构造一个 sudog
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep // 待接收数据的地址保存下来
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg) // 进入 Channel 的等待接收队列
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2) // 将当前 goroutine 挂起
// 被唤醒了,接着从这里继续执行一些扫尾工作
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
closed := gp.param == nil
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, !closed
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
上面的代码注释地比较详细,建议读者仔细阅读完源码,再跟着接下来的内容进行梳理:
1)如果 channel 是一个空值(nil),在非阻塞模式下,会直接返回。在阻塞模式下,会调用 gopark 函数挂起 goroutine,这个会一直阻塞下去。因为在 channel 是 nil 的情况下,要想不阻塞,只有关闭它,但关闭一个 nil 的 channel 又会产生 panic,所以 goroutine 没有机会被唤醒了。
2)在非阻塞模式下,不用获取锁,快速检测到失败并且返回。顺带插一句,平时在写代码的 时候,找到一些边界条件,快速返回,能让代码逻辑更清晰,因为接下来处理正常情况就更聚焦 了,看代码的人也能专注地看核心代码逻辑。
当观察到 channel 没准备好接收:
// src/runtime/chan.go
// empty 报告从 channel 读是否应该被 block,也就是 channel 是“空”的,才会被 block
func empty(c *hchan) bool {
// 一旦 channel 被创建,c.dataqsiz 就不会被修改
if c.dataqsiz == 0 {
// sendq 里是否有向 channel 发送的 goroutine。若没有,则说明 channel 为 “空”
return atomic.Loadp(unsafe.Pointer(&c.sendq.first)) == nil
}
// 缓冲型的 channel,元素个数是否为 0
return atomic.Loaduint(&c.qcount) == 0
}
2
3
4
5
6
7
8
9
10
11
12
1)非缓冲型,等待发送列队里没有 goroutine 在等待。
判断是非缓冲型,直接判断 hchan 的 dataqsize 是否为 0 即可,因为 hchan 一旦初始化了,dataqsize 就不会被更改了,dataqsize 是指底层循环数组的长度。
2)缓冲型,但 buf 里没有元素。
之后,又观察到 closed 等于 0,即 channel 未关闭。
因为 channel 不可能被重复打开,所以前一个观测的时候,channel 也是未关闭的,因此在这种情况下可以直接宣布接收失败,快速返回。因为没被选中,也没接收到数据,所以返回值为 (false, false)。
接下来的操作,首先会上一把锁,粒度比较大。
如果 channel 已关闭,并且循环数组 buf 里没有元素。对应非缓冲型关闭、缓冲型关闭但 buf 无元素的情况,返回对应类型的零值,并且 received 标识是 false,告诉调用者此 channel 已关闭,取出来的值并不是正常由发送者发送过来的数据。但是如果处于 select 语境下,这种情况是被选中了的。很多将 channel 用作通知信号的场景就是应用于这里。
如果有等待发送的队列,说明 channel 已经满了,要么是非缓冲型的 channel,要么是缓冲型的 channel,但 buf 满了。这两种情况下都可以正常接收数据。调用 recv 函数:
// src/runtime/chan.go
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.dataqsiz == 0 { // 如果是非缓冲型的 channel
if raceenabled {
racesync(c, sg)
}
if ep != nil { // 未忽略接收的数据
// 直接复制数据,从 sender goroutine -> receiver goroutine
recvDirect(c.elemtype, sg, ep)
}
} else {
// 缓冲型的 channel,但 buf 已满
// 将循环数组 buf 队首的元素复制到接收数据的地址
// 将发送者的数据入队。实际上这时 revx 和 sendx 值相等
// 找到接收游标
qp := chanbuf(c, c.recvx)
//……
if ep != nil { // 将接收游标处的数据复制给接收者
typedmemmove(c.elemtype, ep, qp)
}
// 将发送者数据复制到 buf
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++ // 更新游标值
if c.recvx == c.dataqsiz { // 如果接收游标等于 buf 的容量 给接收游标置0
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
sg.elem = nil
gp := sg.g
unlockf() // 解锁
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1) // 唤醒发送的 goroutine。需要等到调度器的“光临”
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
如果是非缓冲型的,就直接从发送者的栈复制到接收者的栈:
// src/runtime/chan.go
func recvDirect(t *_type, sg *sudog, dst unsafe.Pointer) {
src := sg.elem
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size)
memmove(dst, src, t.size)
}
2
3
4
5
6
7
否则,就是缓冲型 channel,而 buf 又满了的情形。说明发送游标和接收游标重合了,因此需要先找到接收游标:
// src/runtime/chan.go
func chanbuf(c *hchan, i uint) unsafe.Pointer {
return add(c.buf, uintptr(i)*uintptr(c.elemsize))
}
2
3
4
5
将该处的元素复制到接收地址,然后将发送者待发送的数据复制到接收游标处。这样就完成了接收数据和发送数据的操作。接着,分别将发送游标和接收游标向前进一,如果发生 “环绕”,再 从 0 开始。
最后,取出 sudog 里的 goroutine,调用 goready 将其状态改成 “runnable”,待发送者被唤醒,等待调度器的调度。
再次回到 chanrecv 函数:
1)此时, 如果 channel 的 buf 里还有数据, 说明可以比较正常地接收。 注意, 即使是在 channel 已经关闭的情况下,也是可以走到这里的。这一步比较简单,正常地将 buf 里接收游标处的数据复制到接收数据的地址。
2)最后一步,走到这里来的情形是要阻塞的。当然,如果 block 传进来的值是 false,那就不阻塞,直接返回就好了。
3)真要阻塞时,先构造一个 sudog,保存各种值。注意,这里会将接收数据的地址存储到了 elem 字段,当被唤醒时,接收到的数据就会保存到这个字段指向的地址。然后将 sudog 添加到 channel 的 recvq 队列里。调用 goparkunlock 函数将 goroutine 挂起。
剩下的代码就是 goroutine 被唤醒后的各种收尾工作了。
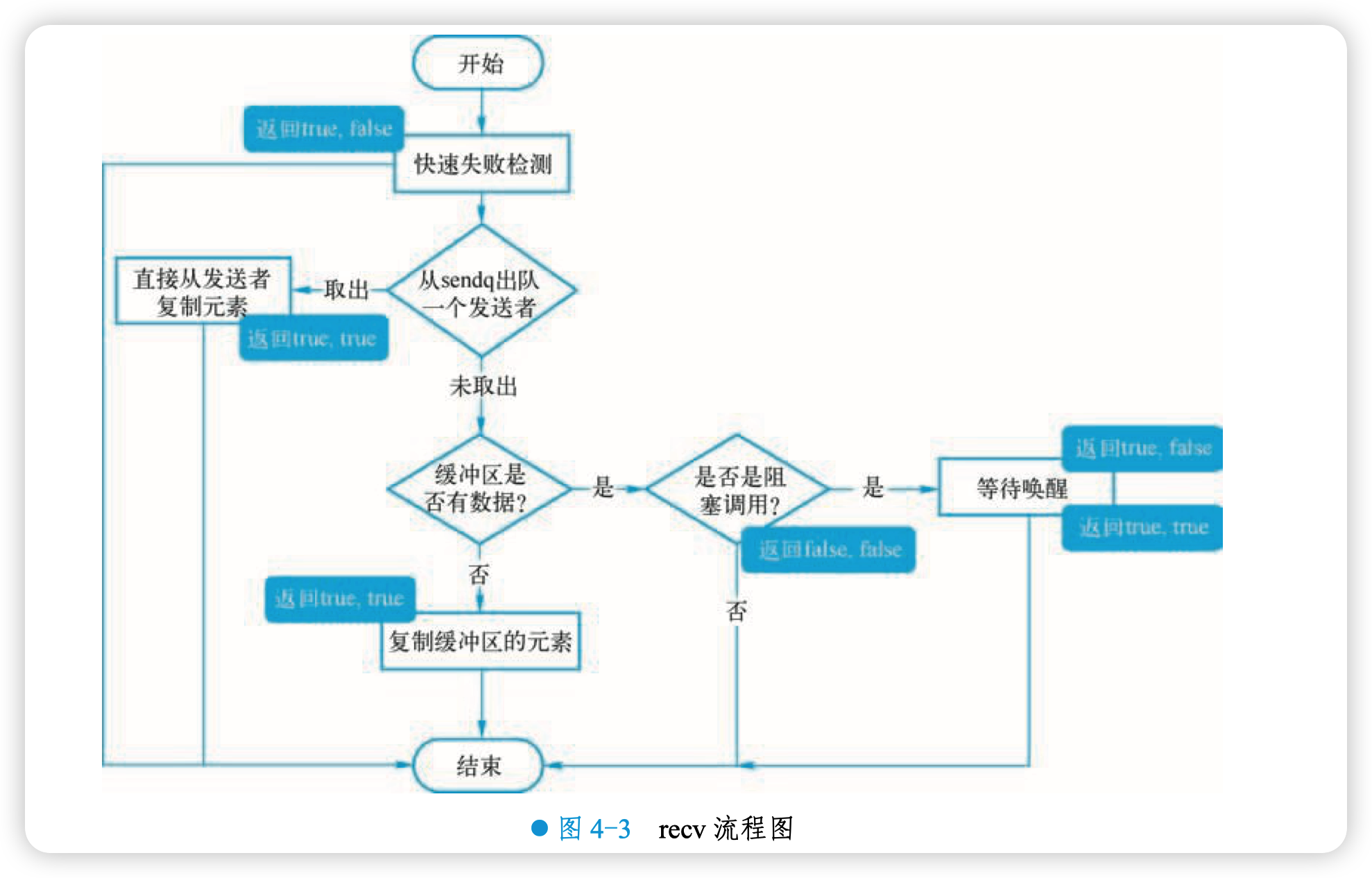
用图 4-3 所示流程图来总结一下:
# 2. 案例分析
从 channel 接收数据以及向 channel 发送数据的过程都会使用下面这个例子来进行说明:
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int)
go GoroutineA(ch)
go GoroutineB(ch)
ch <- 3
time.Sleep(time.Second)
}
func GoroutineA(a <-chan int) {
val := <-a
fmt.Println("G1 received data", val)
return
}
func GoroutineB(b <-chan int) {
val := <-b
fmt.Println("G2 received data", val)
return
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
首先创建了一个无缓冲的 channel,接着启动两个 goroutine,并将前面创建的 channel 作为函数参数传递进去。然后,向这个 channel 中发送数据 3,最后主动休眠 1s 后主程序退出。
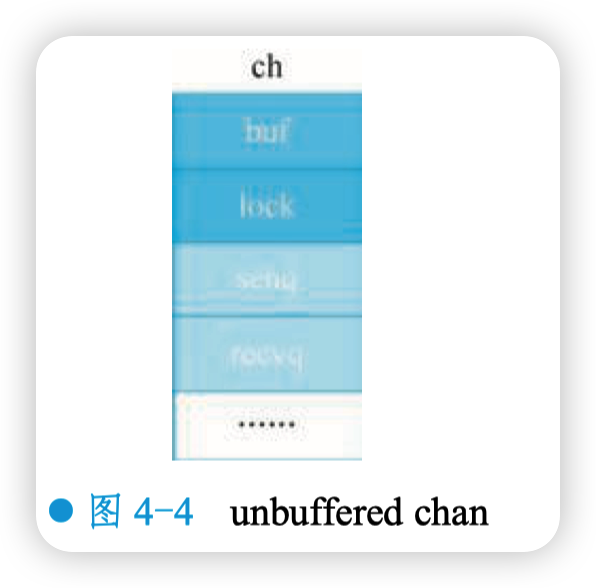
Main 函数第 1 行创建了一个非缓冲型的 channel,只看 chan 结构体中的一些重要字段,来从整体层面看一下 chan 的状态。一开始是一个初始化的 channel,什么都没有,如图 4-4 所示。
接着,main 函数第 2、3 行分别创建了一个 goroutine,各自执行 了一个接收操作。通过前面的源码分析得知,这两个 goroutine (后文分 别称为 G1 和 G2)都会被阻塞在接收操作。G1 和 G2 会挂在 channel 的 recq 队列中,形成一个双向循环链表。
在程序向 chan 发送 3 之前,chan 的一些关键字段的值见表 4-1。

chan struct at the runtime
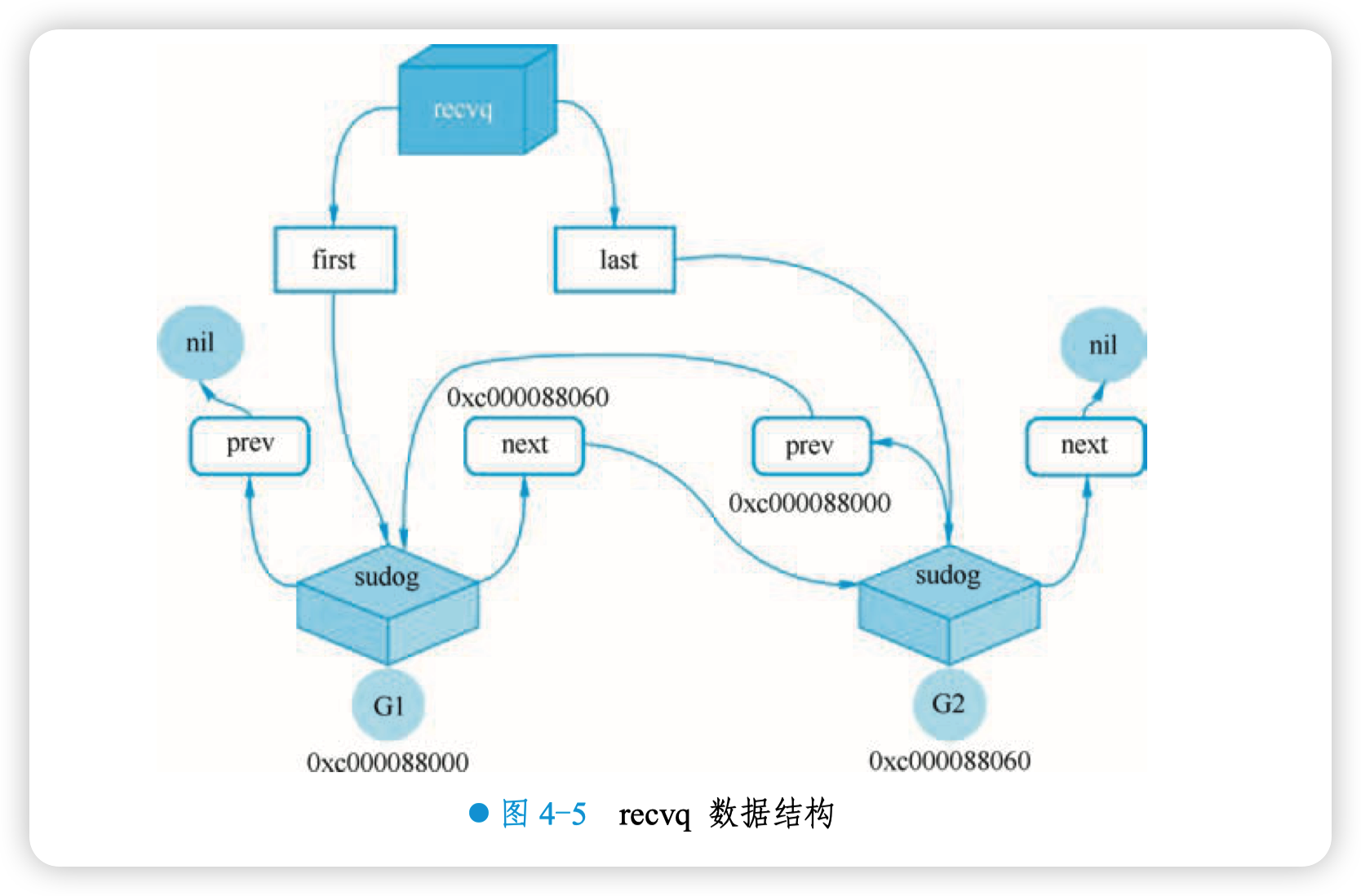
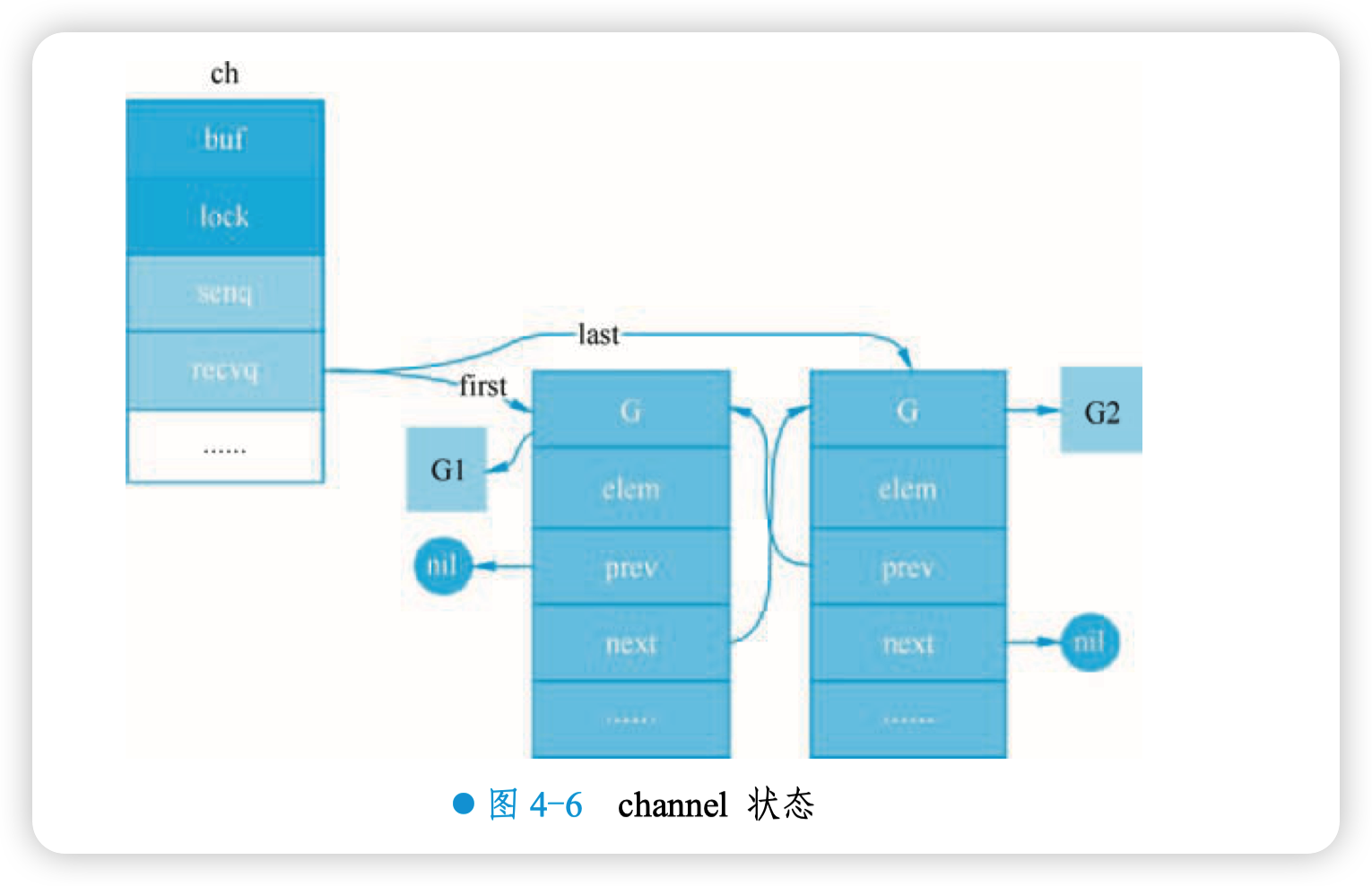
字段 buf 指向一个长度为 0 的数组, qcount 为 0, 表示 channel 中没有元素。 重点关注 recvq 和 sendq, 它们是 waitq 结构体, 而 waitq 实际上就是一个双向链表, 链表的元素是 sudog。而 sudog 结构体包含 g 字段,g 表示一个 goroutine,所以 sudog 可以简单地看成一个 goroutine。字段 recvq 存储那些尝试读取 channel 但被阻塞的 goroutine,sendq 则存储那些尝试写入 channel,但被阻塞的 goroutine。
此时,可以看到,recvq 里挂了两个 goroutine,也就是前面启动的 G1 和 G2。因为没有元素给 goroutine 接收,而 channel 又是无缓冲类型,所以 G1 和 G2 被阻塞。另外,sendq 上则没有存储被 阻塞的 goroutine。
字段 recvq 的结构如图 4-5 所示。
再从整体上来看一下 chan 此时的状态,如图 4-6 所示。
G1 和 G2 被挂起了,状态是 waiting。关于 goroutine 以及调度器相关内容不是本节的重点, 简单说明一下:goroutine 由 runtime 进行管理,作为对比,内核线程由 OS 进行管理。goroutine 更轻量,因此 Go 程序中可以轻松创建数万 goroutine。
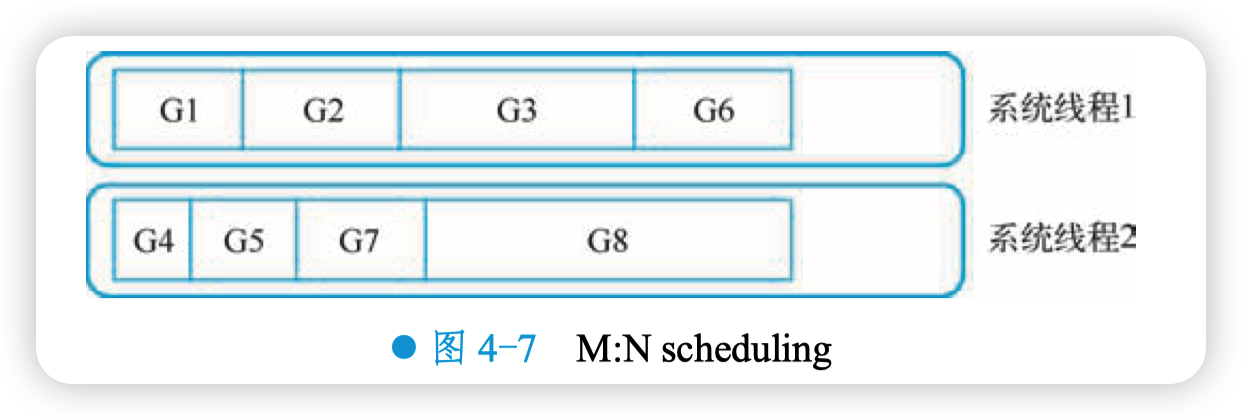
一个内核线程可以管理多个 goroutine,当其中一个 goroutine 阻塞时,内核线程可以调度其他的 goroutine 来运行,而内核线程本身不会阻塞。这就是通常所说的 M:N 模型,如图 4-7 所示。
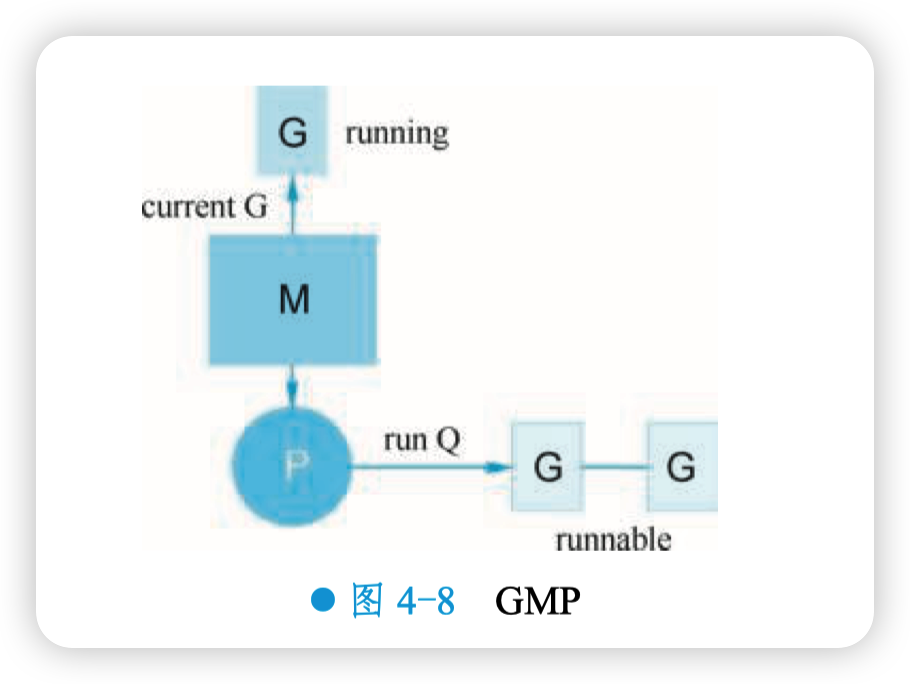
M:N 模型通常由三部分构成:G、P、M。G 是待运行的 goroutine;P 是逻辑处理器,保存 goroutine 运行所需要的上下文,它还维护了可运行(runnable)的 goroutine 列表;M 是内核线程,负责运行 goroutine。P 和 M 是 G 运行的基础,如图 4-8 所示。
继续回到例子。假设只有一个 M,当 G1(go GoroutineA (ch)) 运行到 val := <- a 时,它由 本来的 running 状态变成了 waiting 状态(这是调用了 gopark 之后的结果),如图 4-9 所示。

G1 脱离与 M 的绑定,但调度器可不会让 M “闲” 着, 所以会接着调度另一个 goroutine 来运行,如图 4-10 所示。
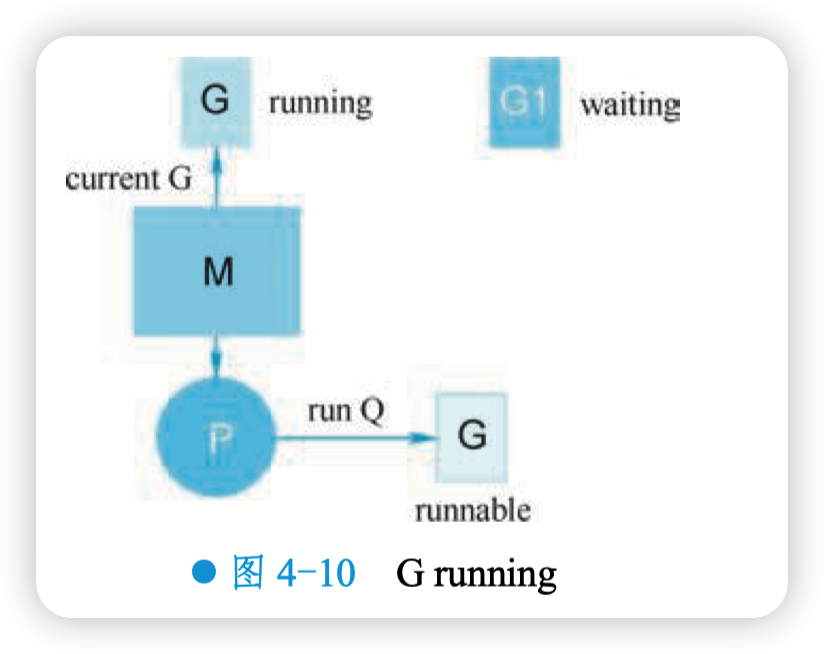
G2 也是同样的遭遇。现在 G1 和 G2 都被挂起了,等待 着一个 sender 往 channel 里发送数据,才能 “得到解救”。
# 发送过程
# 1. 源码分析
发送操作最终会调用 chansend 函数,直接贴上源码。同样 大部分都注释了,可以看懂主流程:
// src/runtime/chan.go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
if c == nil { // 如果 channel 是 nil
if !block { // 不能阻塞,直接返回 false,表示未发送成功
return false
}
// 当前 goroutine 被挂起
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// ……
// 对于不阻塞的 send,快速检测失败场景
//
// 如果 channel 未关闭且 channel 没有多余的缓冲空间。这可能是:
// 1. channel 是非缓冲型的,且等待接收队列里没有 goroutine
// 2. channel 是缓冲型的,但循环数组已经装满了元素
if !block && c.closed == 0 && full(c) {
return false
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
lock(&c.lock) // 锁住 channel,并发安全
if c.closed != 0 { // 如果 channel 关闭了
unlock(&c.lock) // 解锁
panic(plainError("send on closed channel")) // 直接 panic
}
// 如果接收队列里有 goroutine,直接将要发送的数据复制到接收 goroutine
if sg := c.recvq.dequeue(); sg != nil {
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// 对于缓冲型的 channel,如果还有缓冲空间
if c.qcount < c.dataqsiz {
// qp 指向 buf 的 sendx 位置
qp := chanbuf(c, c.sendx)
// ……
typedmemmove(c.elemtype, qp, ep) // 将数据从 ep 处复制到 qp
c.sendx++ // 发送游标值加 1
if c.sendx == c.dataqsiz { // 如果发送游标值等于容量值,游标值归 0
c.sendx = 0
}
c.qcount++ // 缓冲区的元素数量加 1
unlock(&c.lock) // 解锁
return true
}
if !block { // 如果不需要阻塞,则直接返回错误
unlock(&c.lock)
return false
}
// channel 满了,发送方会被阻塞。接下来会构造出一个 sudog
// 获取当前 goroutine 的指针
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg) // 当前 goroutine 进入发送等待队列
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2) // 当前 goroutine 被挂起
KeepAlive(ep)
// 从这里开始被唤醒了(channel 有机会可以发送了)
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if gp.param == nil {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
// 被唤醒后,channel 关闭了,导致 panic
panic(plainError("send on closed channel"))
}
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
// 去掉 mysg 上绑定的 channel
mysg.c = nil
releaseSudog(mysg)
return true
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
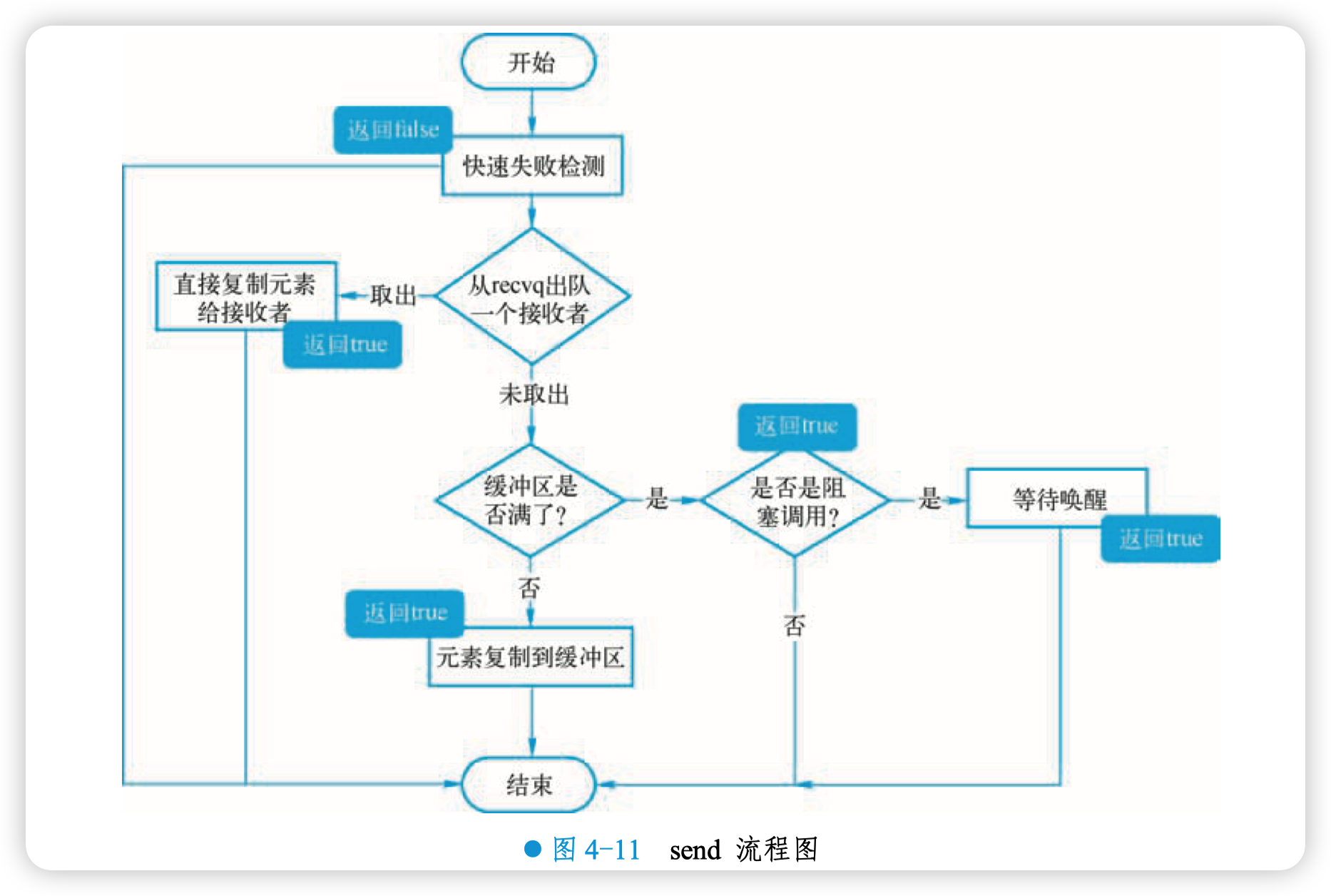
上面的代码注释地比较详细了,来详细看看。首先是不加锁快速检测失败并且返回的三种情况:
1)如果检测到 channel 是空的,并且是一个非阻塞型地发送,直接返回 false,通知发送失败。
2)如果检测到 channel 是空的,并且属于阻塞型发送,那么当前 goroutine 就会被挂起,并且永远不会被唤醒。
3)对于不阻塞的发送操作,如果 channel 未关闭并且 “满了”,说明:①channel 是非缓冲型的,且等待接收队列里没有 goroutine;②channel 是缓冲型的,但循环数组已经装满了元素。直接返回 false。
对于最后一点,runtime 源码里的注释内容比较多。这一条判断语句是为了在不阻塞发送的场景下快速检测到发送失败,快速返回。
// src/runtime/chan.go
// full 反应向 channel 发送元素是否应该被阻塞,阻塞的原因是已满
func full(c *hchan) bool {
// c.dataqsiz 不可变,可以随时并发安全地读
if c.dataqsiz == 0 {
return c.recvq.first == nil
}
return c.qcount == c.dataqsiz
}
2
3
4
5
6
7
8
9
10
注释里主要讲为什么这一块可以不加锁,详细解释一下:if 条件里先读取了两个变量,block 和 c.closed,block 是函数的参数,不会变;c.closed 可能被其他 goroutine 改变,因为没加锁,这 是 “与” 条件前面的两个表达式。
最后一项, 也就是 full 函数里的内容。 涉及三个变量:c.dataqsiz, c.recvq.first, c.qcount。 c.dataqsiz == 0 && c.recvq.first == nil 指的是非缓冲型的 channel,并且 recvq 里没有等待接收的 goroutine;c.dataqsiz > 0 && c.qcount == c.dataqsiz 指的是缓冲型的 channel,但循环数组已经满了。 这里 c.dataqsiz 实际上也不会被修改, 在创建的时候就已经确定了。 不加锁真正影响的是 c.qcount 和 c.recvq.first。
当发现 c.closed == 0 为真,也就是 channel 未被关闭,再去检测第三部分的条件时,观测到 c.recvq.first == nil 或者 c.qcount == c.dataqsiz 时,就将这次发送操作判定为失败,快速返回 false。
这里涉及两个观测项:channel 未关闭、channel 满了。这两项都会因为没加锁而出现观测前后不一致的情况。例如,先观测到 channel 未关闭,再观察到 channel 满了,这时以为能满足这个 if 条件了,但是如果这时 c.closed 变成 1,这时其实就不满足条件了,因为没加锁,所以 c.closed 可能会发生变化。
但是,当观测到 “满了” 时,说明前面观测到 closed == 0 为真,这是依据 && 语句的求值顺序决定:如果已经检测到前一个条件为假,不会继续检测其他条件。并且一个 closed channel 不能将 channel 状态从 “满了” 变成 “没满”。即使现在 c.closed == 1 为真,即 channel 是在这两个观测中间被关闭的,那也说明在这两个观测中间,channel 满足两个条件:未关闭和 “满了”,这时, 直接返回 false 也是没有问题的。
这部分解释比较 “绕”,其实这样做的目的就是少获取一次锁,提升性能。
下面的操作是在加锁的情况下进行:
1)如果检测到 channel 已经关闭,直接 panic。
2)如果能从等待接收队列 recvq 里出队一个 sudog(代表一个 goroutine),说明此时 channel 是空的,没有元素,所以才会有等待接收者。这时调用 send 函数将元素直接从发送者的栈复制到 接收者的栈,由 sendDirect 函数完成复制。
// src/runtime/chan.go
// send 函数处理向一个空的 channel 发送元素
// ep 指向被发送的元素,会被直接复制到接收的 goroutine
// 之后,接收元素的 goroutine 会被唤醒
// c 必须是空的(因为等待队列里有 goroutine,肯定是空的)
// c 必须被上锁,发送操作执行完后,会使用 unlockf 函数解锁
// sg 必须已经从等待队列里取出来了
// ep 必须是非空,并且它指向堆或调用者的栈
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// 省略一些竞态检测
// ……
// sg.elem 指向接收到的值存放的位置,如 val <- ch,指的就是 &val
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep) // 直接复制内存(从发送者到接收者)
sg.elem = nil
}
gp := sg.g // sudog 上绑定的 goroutine
unlockf() // 解锁
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1) // 唤醒接收的 goroutine. skip 和打印栈相关,暂时不理会
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
继续看 sendDirect 函数:
// src/runtime/chan.go
// 向一个非缓冲型的 channel 发送数据、从一个无元素的(非缓冲型或缓冲型但空)的 channel
// 接收数据,都会导致一个 goroutine 直接操作另一个 goroutine 的栈
// 由于 GC 假设对栈地写操作只能发生在 goroutine 正在运行中并且由当前 goroutine 来写
// 所以这里实际上违反了这个假设。可能会造成一些问题,所以需要用到写屏障来规避
func sendDirect(t *_type, sg *sudog, src unsafe.Pointer) {
// src 在当前 goroutine 的栈上,dst 是另一个 goroutine 的栈
// 直接进行内存"搬迁"
// 如果目标地址的栈发生了栈收缩,当读出了 sg.elem 后
// 就不能修改真正的 dst 位置的值了
// 因此需要在读和写之前加上一个屏障
dst := sg.elem
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size)
memmove(dst, src, t.size)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这里涉及一个 goroutine 直接写另一个 goroutine 栈的操作,一般而言,不同 goroutine 的栈是各自独有的,这样实际上也违反了 GC 的一些假设。为了不出问题,写的过程中增加了写屏障, 保证正确地完成写操作。这样做的好处是减少了一次内存复制:不用先复制到 channel 的 buf,直接由发送者到接收者,“没有中间商赚差价”,效率得以提高。
接着,解锁、唤醒接收者,接收者也得以 “重见天日”,当被调度器调度执行时,就可以继续执行接收操作之后的代码了。
继续回到 chansend 函数:
1)如果 c.qcount < c.dataqsiz,说明缓冲区可用(肯定是缓冲型的 channel),先通过函数获取待发送元素应该去的位置:
// src/runtime/chan.go
qp := chanbuf(c, c.sendx)
// 返回循环队列里第 i 个元素的地址处
func chanbuf(c *hchan, i uint) unsafe.Pointer {
return add(c.buf, uintptr(i)*uintptr(c.elemsize))
}
2
3
4
5
6
7
调用 typedmemmove 函数将 ep 指向的待发送的元素复制到循环数组中 qp 指向的位置:
typedmemmove(c.elemtype, qp, ep)
游标 c.sendx 指向下一个待发送元素在循环数组中的位置,之后 c.sendx 加 1,元素总量加 1,最后,解锁并返回。
2)如果没有命中以上条件的,说明 channel 已经满了。不管这个 channel 是缓冲型的还是非缓冲型的,都要将这个 sender “关起来”(goroutine 被阻塞)。如果 block 为 false,直接解锁,返回 false。
3)最后就是真的需要被阻塞的情况。 先构造一个 sudog, 将其入队(channel 的 sendq 字段)。然后调用 goparkunlock 将当前 goroutine 挂起,并解锁,等待合适的时机再唤醒 goroutine。
唤醒之后,从 goparkunlock 下一行代码开始继续往下执行。
这里有一些绑定操作, sudog 通过 g 字段绑定 goroutine, 而 goroutine 通过 waiting 绑定 sudog, sudog 还通过 elem 字段绑定待发送元素的地址, 以及 c 字段绑定被 “困” 在此处的 channel。
所以,待发送的元素地址其实是存储在 sudog 结构体里,也就是当前 goroutine 里。
用如图 4-11 所示流程图来总结一下:
# 2. 案例分析
分析完源码,接着来分析例子,代码如下:
func GoroutineA(a <-chan int) {
val := <- a
fmt.Println("goroutine A received data: ", val)
return
}
func GoroutineB(b <-chan int) {
val := <- b
fmt.Println("goroutine B received data: ", val)
return
}
func main() {
ch := make(chan int)
go GoroutineA(ch)
go GoroutineB(ch)
ch <- 3
time.Sleep(time.Second)
ch1 := make(chan struct{})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在 4.3.3 小节里说到 G1 和 G2 现在被 “挂” 起来了,等待 sender 的解救。在第 17 行,主 协程向 ch 发送了一个元素 3,来看看接下来会发生什么。
根据前面源码分析的结果得知,sender 发现 ch 的 recvq 里 有 receiver 在等待着接收, 就会出队一个 sudog, 把 recvq 里 first 指针的 sudog “推举” 出来了, 并将其加入 P 的可运行 goroutine 队列中。
然后,sender 把发送元素复制到 sudog 的 elem 地址处,最后 会调用 goready 将 G1 唤醒,状态变为 runnable,如图 4-12 所示。
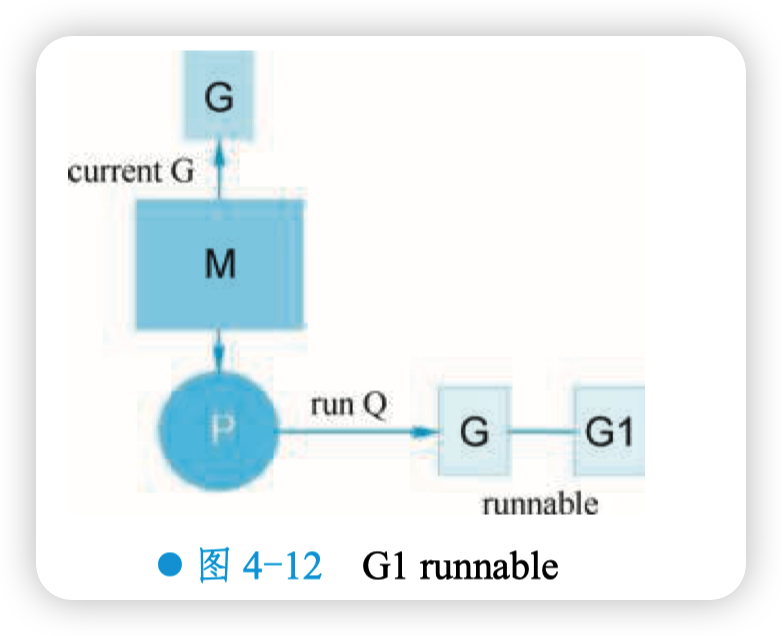
当调度器调度到 G1 时, 将 G1 变成 running 状态, 执行 goroutineA 接下来的代码,G 表示其他可能有的 goroutine。
这里其实涉及一个协程写另一个协程栈的操作。有两个 receiver 在 channel 的一边 “虎视眈 眈” 地等着,这时 channel 另一边来了一个 sender 准备向 channel 发送数据,为了高效,不通过 channel 的 buf “中转” 一次,直接从源地址把数据复制目的地址就可以了,如图 4-13 所示。
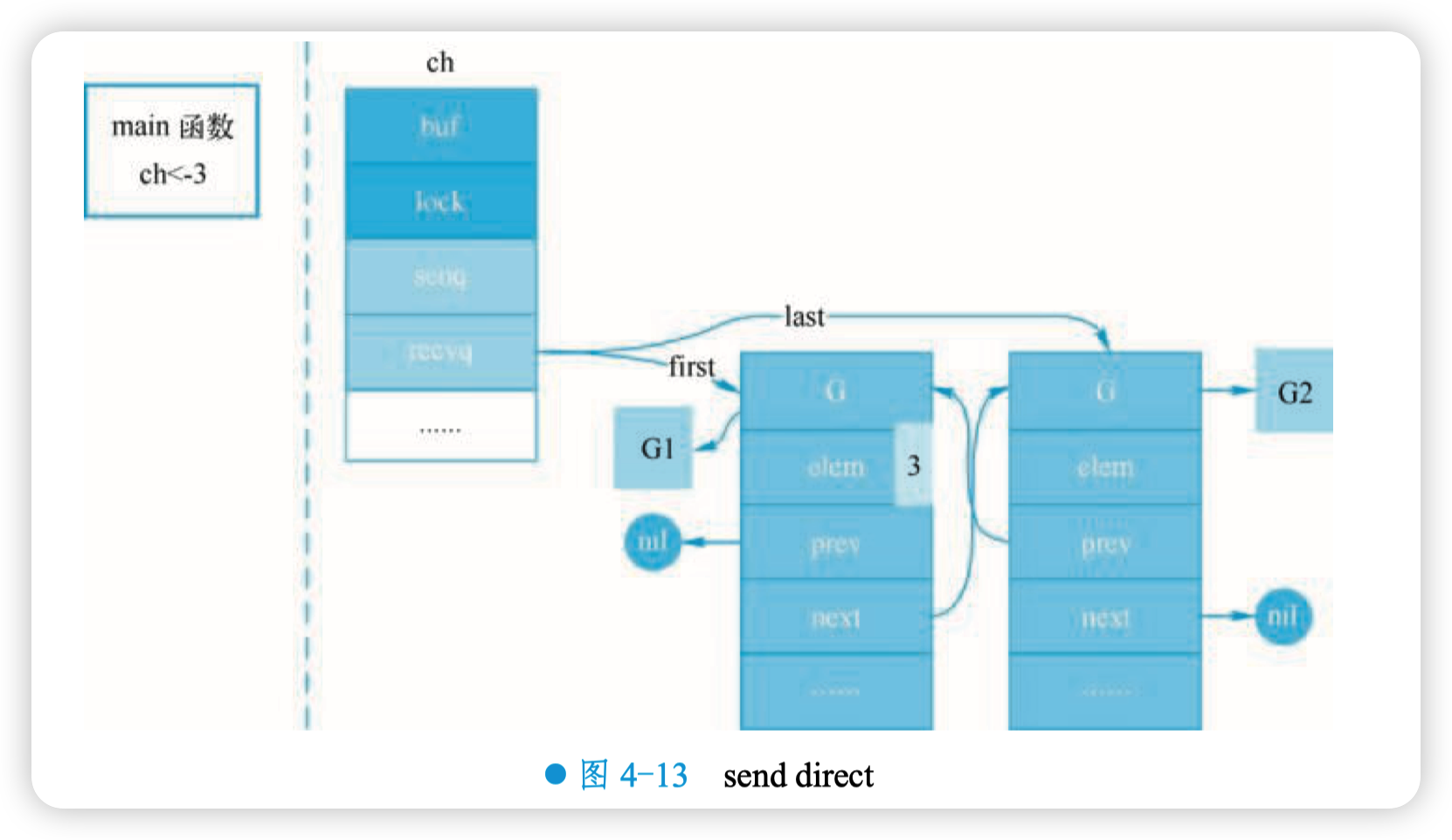
上图是一个示意图,3 会被复制到 G1 栈上的某个位置,也就是 val 的地址处,保存在 elem 字段。
# 收发数据的本质
收发数据的本质可以用一句话回答:
All transfer of value on the go Channels happens with the copy of value.
就是说 channel 的发送和接收操作本质上都是 “值的复制”,无论是从 sender goroutine 的栈到 chan buf, 还是从 chan buf 到 receiver goroutine, 或者是直接从 sender goroutine 到 receiver goroutine。
来看一个例子:
type user struct {
name string
age int8
}
var u = user{name: "Ankur", age: 25}
var g = &u
func modifyUser(pu *user) {
fmt.Println("modifyUser Received Vaule", pu)
pu.name = "Anand"
}
func printUser(u <-chan *user) {
time.Sleep(2 * time.Second)
fmt.Println("printUser GoRoutine called", <-u)
}
func main() {
c := make(chan *user, 5)
c <- g
fmt.Println(g)
// modify g
g = &user{name: "Ankur Anand", age: 100}
go printUser(c)
go modifyUser(g)
time.Sleep(5 * time.Second)
fmt.Println(g)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
运行结果:
&{Ankur 25}
modifyUser Receiverd value &{Ankur Anand 100}
printUser GoRoutine called &{Ankur 25}
&{Anand 100}
2
3
4
原书中有误,这边已改正。
这里就是一个很好的 share memory by communicating 的例子,如图 4-14 所示。
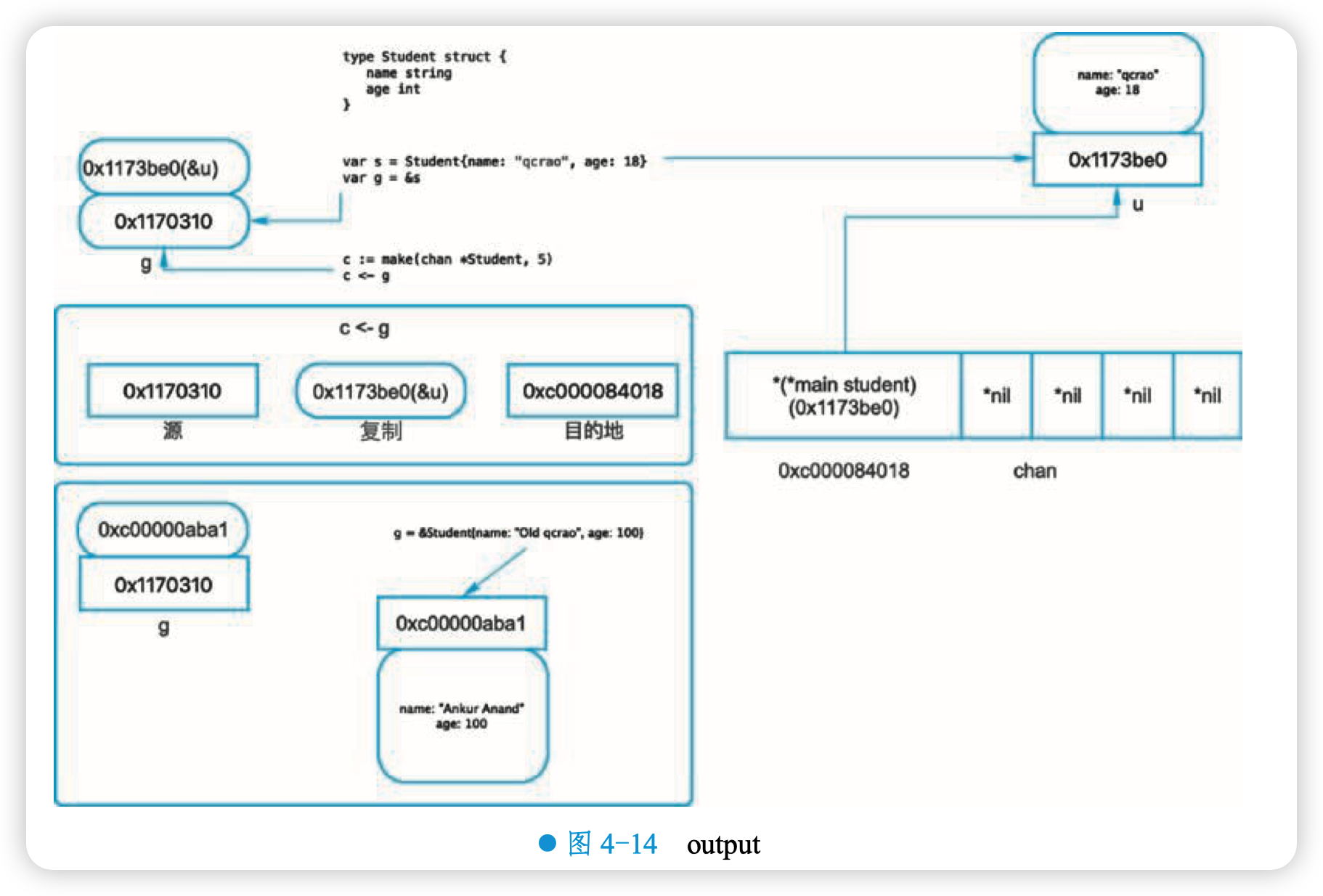
如上图所示,一开始构造一个结构体 u,地址是 0x1173be0,图中右上地址的上方就是它的内容。接着把 &u 赋值给指针 g,g 的地址是 0x1170310,它的内容就是一个地址,指向 u。
在 main 函数里,先把 g 发送到 c,根据 copy value 的本质,进入到 chan buf 里地就是 0x1173be0,它是指针 g 的值(不是它指向的内容),所以打印从 channel 接收到的元素时,它就 是 &{qcrao 25}。因此,这里并不是将指针 g “发送” 到了 channel 里,只是复制它的值而已。
再强调一次:
Remember all transfer of value on the go Channels happens with the copy of value. 即 channel 的发送和接收操作本质上都是 “值的复制”。