 Raft 共识算法(及 etcd/raft 源码解析)
Raft 共识算法(及 etcd/raft 源码解析)
本文引自 [译] [论文] Raft 共识算法(及 etcd/raft 源码解析)(USENIX, 2014) (opens new window)
# 译者序
本文翻译自 USENIX 2014 论文 In Search of an Understandable Consensus Algorithm (Extended Version) (opens new window) ,文中提出了如今已广泛使用的 Raft 共识算法。
在 Raft 之前,Paxos 几乎是共识算法的代名词,但它有两个严重缺点:
- 很难准确理解(即使对专业研究者和该领域的教授)
- 很难正确实现(复杂 + 某些理论描述比较模糊)
结果正如 Chubby(基于 Paxos 的 Google 分布式锁服务,是 Google 众多全球分布式系统的基础)开发者所说:“Paxos 的算法描述和真实需求之间存在一个巨大鸿沟,...... 最终的系统其实将建立在一个没有经过证明的协议之上”。对于大学教授来说,还有一个更实际的困难:Paxos 复杂难懂,但除了它之外,又没有其他适合教学的替代算法。
因此,从学术界和工业界两方面需求出发,斯坦福大学博士生 Diego Ongaro 及其导师 John Ousterhout 提出了 Raft 算法,它的最大设计目标就是可理解性, 这也是为什么这篇文章的标题是《寻找一种可理解的共识算法》。
与原文的可理解性目标类似,此译文也是出于更好地理解 Raft 算法这一目的。 因此,除了翻译时调整排版并加入若干小标题以方便网页阅读,本文还对照了 etcd/raft v0.4 的实现,这个版本已经实现了 Raft 协议的大部分功能,但还未做工程优化, 函数、变量等大体都能对应到论文中,对理解算法有很大帮助。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
# 摘要
Raft 是一个管理复制式日志(replicated log)的共识算法 (consensus algorithm)。它的最终结果与 (multi-) Paxos 等价,也与 Paxos 一样高效,但结构(structure)与 Paxos 不同 —— 这使得它比 Paxos 更好理解,也更易于构建实际系统。
为易于理解,Raft 在设计上将共识拆分为 leader election、log replication、safety 等几个模块; 另外,为减少状态数量,它要求有更强的一致性(a stronger degree of coherency)。 从结果来看,学生学习 Raft 要比学习 Paxos 容易。
Raft 还引入了一个新的集群变更(添加或删除节点)机制,利用重叠大多数(overlapping majorities)特性来保证安全(不会发生冲突)。
# 1 引言
共识算法使多个节点作为一个整体协同工作,这样部分节点出故障时,系统作为一个整体仍然可用。在构建可靠的大规模软件系统时,共识算法扮演着核心角色。
# 1.1 本文背景与目的
过去十几年,共识算法领域一直被 Paxos 牢牢统治:大部分共识算法的实现都基于 Paxos 或者受其影响,而 Paxos 也成了教学的首要选择。
不幸的是,虽然已经有很多更通俗解释 Paxos 的尝试,但 Paxos 仍然难以理解。 此外,Paxos 需要做很复杂的架构改动才能应用到真实系统中。因此, 系统开发者和学生都对 Paxos 感到困惑 —— 我们自己也是如此,在经历了一番挣扎之后,我们最终决定寻找一种新的、能为真实系统和日常教学提供更好基础的共识算法。
- 这个新算法的首要目标是可理解性(understandability): 能否提出一个可用于实际系统、能以恰当方式描述、比 Paxos 更容易学习的共识算法?
- 此外,这个算法要能被系统架构师和开发者更直观地理解。 算法能工作固然很重要,但这还不够,还要让人能很直观地理解它为什么可以工作。
# 1.2 研究成果简介
这项工作的成果就是本文将介绍的 Raft 共识算法。 我们特意采取了一些技术来使它更容易理解,包括功能模块分解 (leader election, log replication, and safety) 和状态空间简化(相比于 Paxos,Raft 中不确定性程度和节点不一致的场景数量都变少了)。 一项针对两个学校共计 43 名学生的调查显示,Raft 要比 Paxos 好理解地多: 在学习了这两种算法之后,33 个同学回答 Raft 的问题要比回答 Paxos 的问题好。
Raft 在很多方面与现有的共识算法(例如 Viewstamped Replication)类似,但也有几个新特征:
- Strong leader(强领导者): 使用更强的 leadership 模型。例如, log entries 只会从 leader 往其他节点同步。这简化了 replicated log 的管理,使 Raft 理解上更简单。
- Leader election(领导选举): 使用随机定时器来选举 leader,并复用了任何共识算法本来就都有 heartbeat 机制(只是在 heartbeat 里增加了一点新东西),还能简单、快速地解决冲突。
- Membership changes(节点变更): 使用一种新的联合共识 (joint consensus)方式,特点是新老配置所覆盖的两个大多数(majorities)子集在变更期间是有重叠的,并且集群还能正常工作。
我们认为不管用于教学还是真实系统,Raft 都比 Paxos 和其他共识算法更好,它的优点包括,
- 更简单、更易理解;
- 描述足够详细,易于工业界实现(已经有几种开源实现并在一些公司落地);
- 安全性(无冲突)有规范化描述并经过了证明;
- 效率与其他算法相当。
# 1.3 本文组织结构
本文接下来的内容安排如下:
- Section 2:介绍 replicated state machine;
- Section 3:讨论 Paxos 的优缺点;
- Section 4:介绍我们针对可理解性所采取的一些设计;
- Section 5-8:描述 Raft 共识算法;
- Section 9:实现与评估;
- Section 10:相关工作。
# 2 复制式状态机(replicated state machines)
讨论 replicated state machines 时,通常都会涉及到共识算法。在这种模型中,若干节点上的状态机计算同一状态的相同副本(compute identical copies of the same state),即使其中一些节点挂掉了,系统整体仍然能继续工作。
# 2.1 使用场景
复制式状态机用于解决分布式系统中的一些容错(fault tolerance)问题。
例如,GFS、HDFS、RAMCloud 等单 leader 大型系统,通常用一个独立的复制式状态机来管理 leader election 及存储配置信息。 Chubby 和 ZooKeeper 也用到了复制式状态机。
# 2.2 状态机架构
复制式状态机通常用 replicated log(复制式日志)实现,如图 1 所示,
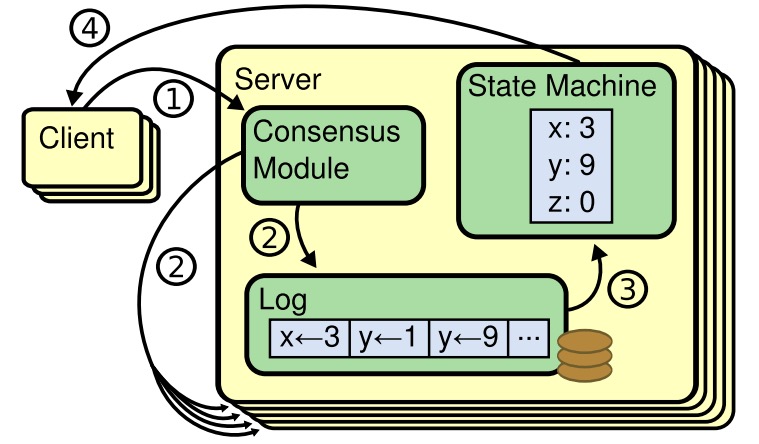
图 1. 复制式状态机架构。 共识算法管理着客户端发来的状态机命令的一个日志副本 (replicated log),状态机以完全相同的顺序执行日志中的命令,因此产生完全相同的输出。